

音声はキーボード、マウスに続く入力インタフェースとして注目されています。スマートフォンにはSiriやGoogle Assistantといったボイスアシスタント機能が組み込まれていますが、自分で開発するアプリから自由に使える訳ではありません。
そこで今回はGoogleが提供している音声認識APIであるGoogle Cloud Speech APIを使ってMonacaアプリで音声認識を実現してみたいと思います。
前提条件
今回作るアプリではマイクを使って録音し、そのデータを音声認識APIに渡します。デバイスやOSのバージョン、使用するアプリの種類によって録音データの音声フォーマットや周波数が異なるため、検証環境を以下に示します。異なる環境では後述する「ファイル読み込み完了時の処理」の変更が必要になる場合があります。
| OS | デバイス | バージョン | 録音アプリ |
|---|---|---|---|
| iOS | iPhone 7 Plus | iOS 10.2 | プリインストールされた録音アプリ |
| Android | Nexus 5 | Android 6.0.1 | 音声レコーダー |
- ピュアAndroidにはプリインストールされている録音アプリがないため、ストアからアプリをインストールしています。
- 上記以外の録音アプリでは、今回作成するアプリからの呼び出しができない可能性があります。
Google Cloud Speech APIとは?
Google Cloud Speech APIは音声認識技術をAPI化したものです。音声ファイルをアップロードすると、各国語のテキストに変換してくれます。もちろん日本語にも対応しています。例えば適当な音声をAPIに投げると、次のようなレスポンスが返ってきます。keyは後述する管理画面で取得できるキーに書き換えます。
$ curl -s -k -H "Content-Type: application/json" https://speech.googleapis.com/v1beta1/speech:syncrecognize?key=APIキー -d @wav.json
{
"results": [
{
"alternatives": [
{
"transcript": "本日は晴天なり",
"confidence": 0.8484849
}
]
}
]
}
見て分かりますが、テキストに変換されたtranscriptが返ってきます。confidenceは信頼性を表し、1に近いほど認識精度の高いデータと言うことになります。プライベートAPIとして公開されているGoogle Speech APIの場合、このalternativesが複数返却され、信頼性がそれぞれ異なります。Google Cloud Speech APIの場合は筆者が試した限りでは常に一つしか返ってこないので、気にする必要はなさそうです。
Google Cloud Speech APIの設定
Google Cloud Speech APIを設定するにはGoogle Cloud Platformにてプロジェクトを作成し、Google Cloud Speech APIを有効にします。
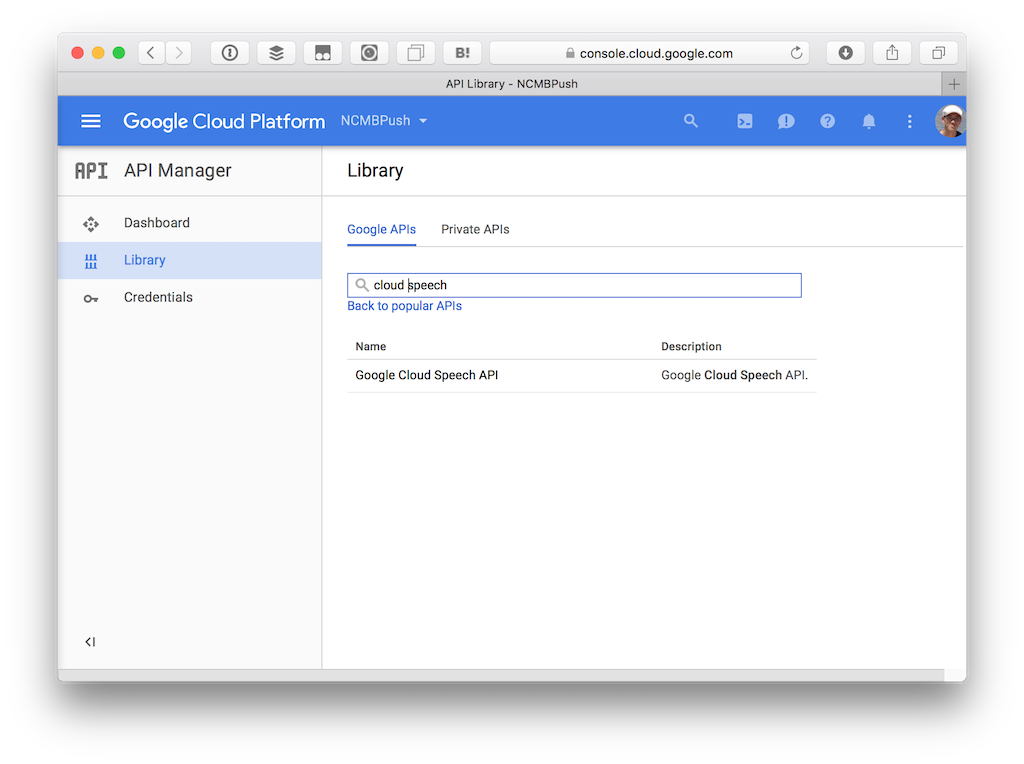
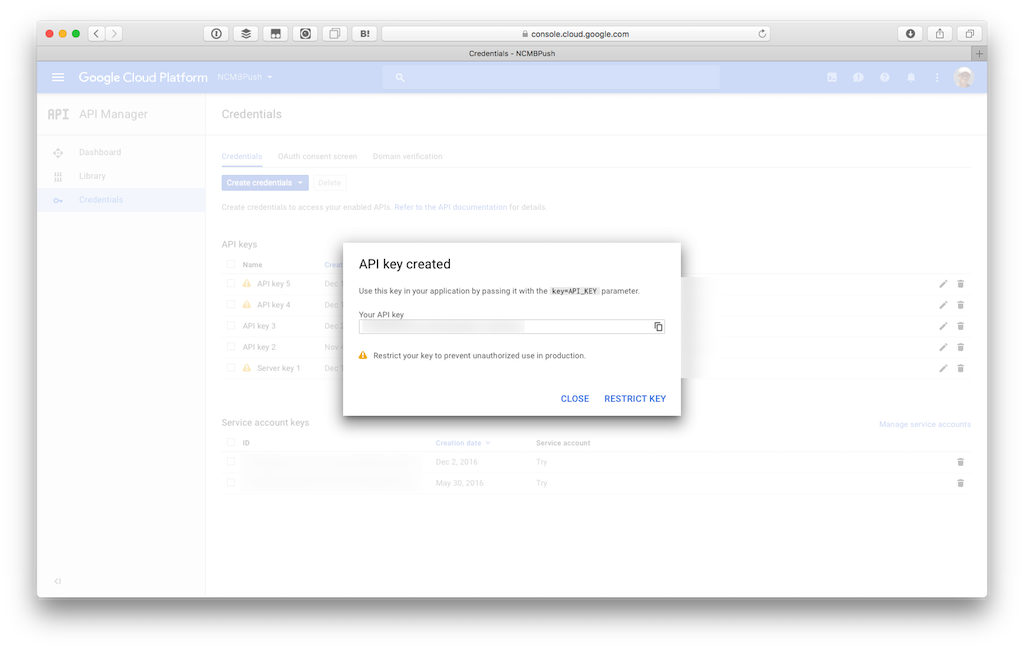
その後Credentialsへ移動してAPI Keyを作成します。必要に応じてアクセス制限を設けてください。
Monacaアプリを作る
今回はOnsen UI V2 JS Minimumをベースにします。プロジェクトを作ったら、Cordovaプラグインとしてcordova-plugin-media-captureをインストールします。これはアプリでマイクを使った音声キャプチャを実現するためのプラグインです。
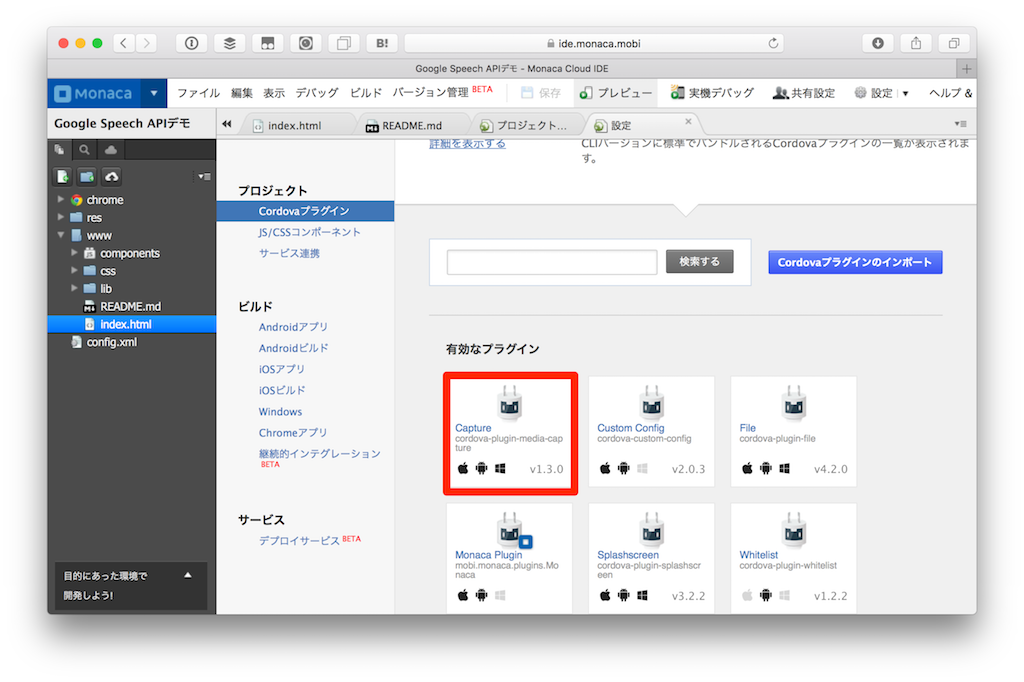
また、Ajaxを実行する関係上、JS/CSSコンポーネントの追加と削除よりjQueryをインストールしておきます。
HTMLを作る
今回のHTMLは次のようになります。キャプチャした音声をそのまま聴けるように audio タグを追加しています。
<ons-page>
<ons-toolbar>
<div class="center">音声認識</div>
</ons-toolbar>
<section style="padding: 8px">
<p></p><br><br>
<ons-button id="capture" modifier="large">音声キャプチャ</ons-button>
<p></p>
<p><audio id="audio" controls></audio></p>
<textarea id="result" class="textarea"></textarea>
</section>
</ons-page>
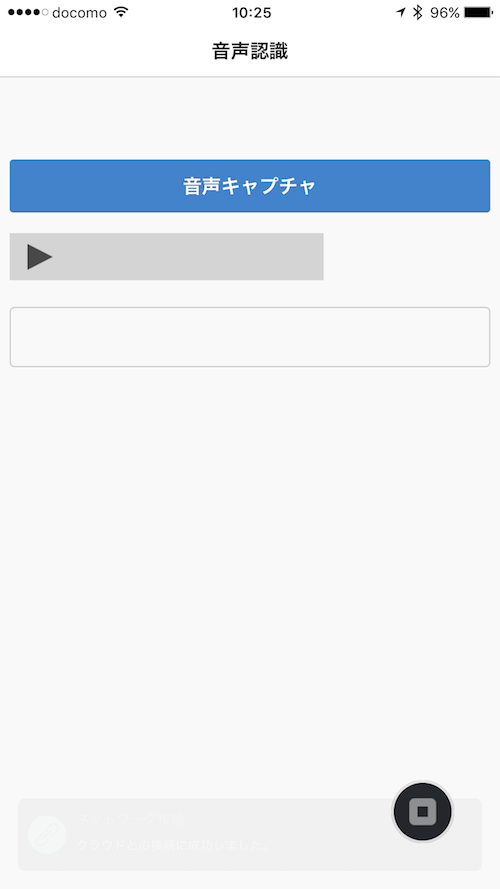
実際の画面は次のようになります。ボタンを押してキャプチャしたら、テキストエリアに結果が返ってくるようにします。
JavaScriptを作る
では具体的な処理を見ていきます。まずボタンを押した際にキャプチャを実行します。
$("#capture").on("click", function() {
navigator.device.capture.captureAudio(app.success, app.error, {limit:15});
});
一つ目の引数が処理成功時のコールバック、次が失敗時のコールバック、最後はキャプチャ設定です。Google Cloud Speech APIには、音声ファイルの長さは1分までという制限があります。あまり長いデータは処理に時間がかかりますので注意してください。
次にキャプチャ完了後の処理を行うappオブジェクトを定義します。全体像は次のようになります。
// Google Cloud Speech APIで使うAPIキー
var key = "";
ons.ready(function() {
var app = {
// ファイルを読み込むためのオブジェクトです
reader: new FileReader(),
// キャプチャ成功時のコールバックです
success: function(files) {
},
// ファイルを読み込むと呼ばれるコールバックです
load_file: function() {
},
// Google Cloud Speech APIをコールします
voice_recognition: function(json) {
},
// キャプチャ失敗時のコールバックです
error: function(error) {
alert("Capture Error:" + error);
}
};
});
キャプチャ成功時の処理
キャプチャが成功したら、FileReaderを使って音声ファイルを読み込みます。今回は audio タグに対してパスを設定することで、その場で再生できるようにしてあります。
success: function(files) {
var file = files[0];
$("#audio").attr("src", file.fullPath);
// ファイルを読み込んだ時のコールバックを指定
app.reader.onloadend = app.load_file;
// Fileオブジェクトを作成します
audioFile = new window.File(
file.name,
file.localURL,
file.type,
file.lastModifiedDate,
file.size
);
// ファイルを読み込みます(Base64で取得できます)
app.reader.readAsDataURL(audioFile);
},
ファイル読み込み完了時の処理
FileReader の readAsDataURL() で読み込むと app.load_file がコールバックされ、音声データがBase64の文字列で取得できます。
iPhone 7 Plus / iOS 10.2 の場合は、音声フォーマットが WAV、周波数が44100になります。
Nexus 5 / Android 6.0.1 で音声レコーダーアプリを呼び出して録音した場合は、音声フォーマットがAMR、周波数が8000になります。そのため、取得した音声フォーマットに応じて Speech APIに渡すJSONの設定を変更しています。
language_code は日本語を解析するために ja_JP を指定してください。
load_file: function() {
// base64文字列を取得
var result = app.reader.result;
var encoding;
var sample_rate;
if(result.indexOf("data:audio/amr;") === 0) {
// 音声データがamrの場合
encoding = "AMR";
sample_rate = 8000;
} else {
// 音声データがwavの場合
encoding = "LINEAR16";
sample_rate = 44100;
}
// data:audio/wav;base64,aaa... といった形式で取得
// されるので、,以降だけにします
var ary = result.split(",");
// Google Cloud Speech APIに投げるデータフォーマットを作成
var json = {
"config": {
"encoding": encoding,
"sample_rate": sample_rate,
"language_code": "ja_JP"
},
"audio": {
"content": ary[1]
}
};
// 音声認識処理を実行します
app.voice_recognition(json);
},
encodingには、上記の他に FLAC/MULAW/AMR_WB を指定することができます。
音声認識処理を実行する
後はAjaxを使ってPOSTメソッドでデータを送るだけです。JSON形式でデータを送って、返却された結果をテキストエリア内に表示しています。今回は音声ファイルを送っているので syncrecognize を指定して同期処理していますが、ストリーミングによる認識にも対応しているようです。
voice_recognition: function(json) {
// AjaxでPOST処理
$.ajax({
type: 'POST',
url: 'https://speech.googleapis.com/v1beta1/speech:syncrecognize?key=' + key,
data: JSON.stringify(json),
dataType:'json',
contentType: 'application/json'
}).done(function(data) {
// 処理結果をテキストエリアに表示
$("#result").val(data.results[0].alternatives[0].transcript);
}).fail(function(error) {
alert("Speech API Error:" + JSON.stringify(error));
});
},
実際に試すと喋った日本語が高い精度でテキスト化されます。ここで見て欲しいのはmonacaがちゃんと英語のスペルになっている点です。
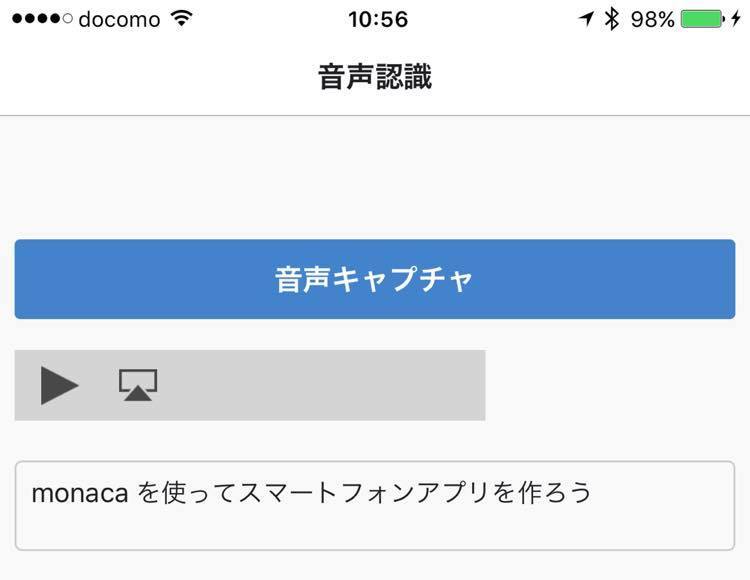
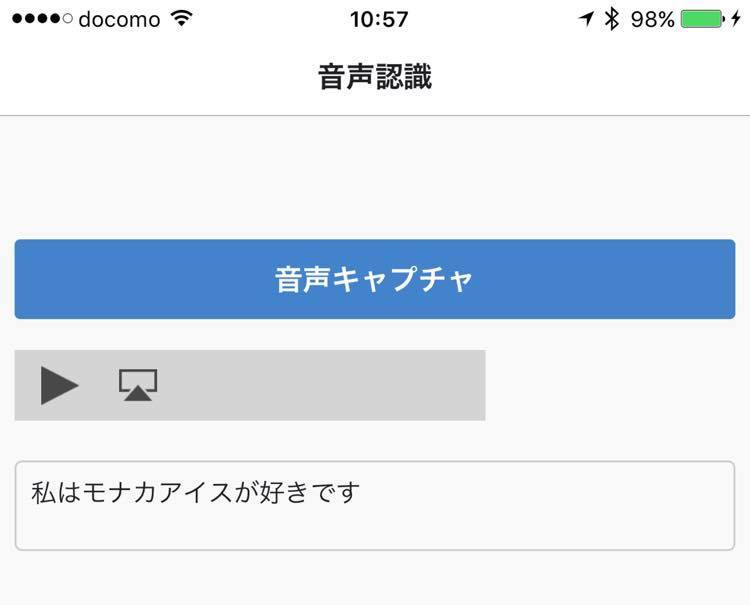
食べ物で認識されるとカタカナのモナカになります。文脈を理解した上でテキスト化されているのが分かります。
Google Cloud Speech APIを使えば音声入力によってアプリを操作したり、入力を代行するのが簡単になります。ぜひ皆さんのアプリにも組み込んでみてください。今回のコードはmoongift/monaca_voice_recognitionにアップしてありますので、実装の参考にしてください。